This section features a comprehensive overview of our presentations, including details on upcoming talks and a complete archive of our past discussions on network inequality and related topics.
Upcoming Talks
No upcoming talks are scheduled at the moment.
Past Talks

No More Fai(r)lure! How Understanding Bias Enables Us to Achieve Fairness
by Marco Favier
13.02.2025 11am CET
Abstract: In decision-making fairness literature, group fairness measures are often used as a proxy to ensure ethical decisions and to constrain the space of possible models to only fair ones. However, little is mathematically understood about the impact of these measures on the final model or whether models that satisfy fairness criteria can truly be considered fair. In this talk, we explore why the standard fairness pipeline can fail drastically without first understanding bias and discuss potential theoretical solutions.

ProbINet: A Python Package for Unified Probabilistic Network Modeling
by Diego Baptista Theuerkauf
06.02.2025 11am CET
Abstract. Recent advances in network analysis have focused on probabilistic generative models that reveal hidden community structures, capture reciprocity, and identify anomalies. By relaxing the common assumption of conditional independence and explicitly modelling edges between pairs of nodes, these models improve performance in tasks such as edge prediction and network reconstruction, and provide deeper insights into the mechanisms of edge formation. However, their fragmented implementations – requiring different dependencies and inconsistent interfaces – limit usability, comparability, and broader impact. To address these challenges, we present ProbINet [6], a unified Python package that integrates these models into a single framework. ProbINet standardizes interfaces, improves usability, and links theoretical principles to implementations, supporting tasks such as community detection, anomaly detection, link prediction, and synthetic data generation. This robust framework ensures accessibility for both researchers and practitioners.

Improving the visibility of minorities through network growth interventions
by Leonie Neuhäuser
21.11.2024 11am CET
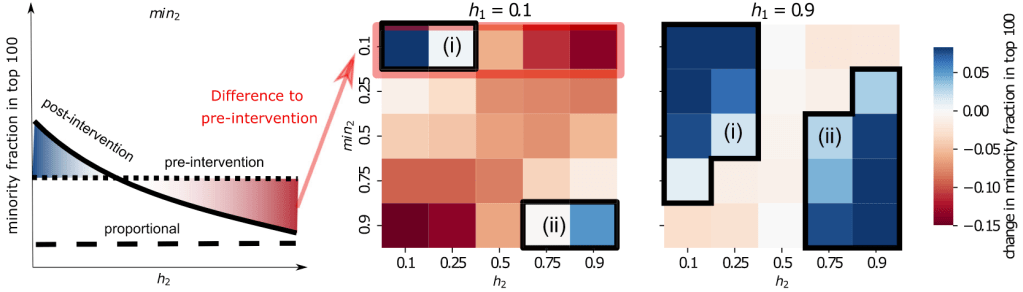
Abstract. Improving the position of minority groups in networks through interventions is a challenge of high theoretical and societal importance. However, a systematic analysis of interventions that alter the network growth process is still missing. In this work, we propose a model to examine how network growth interventions impact the position of minority nodes in degree rankings over time. We distinguish between (i) group size interventions, such as introducing quotas; and (ii) behavioural interventions, such as varying how groups connect to each other. We find that even extreme quotas do not increase minority representation in rankings if the actors in the network do not adopt homophilic behaviour. Thus, interventions need to be coordinated in order to improve the visibility of minorities. In a real-world case study, we explore which interventions can reach gender parity in academia. Our work provides a theoretical and computational framework for investigating the effectiveness of interventions in growing networks.

Social network segregation and barriers of urban mobility
by Balazs Lengyel
26.09.2024 11am CET
Abstract. Social networks amplify inequalities by fundamental mechanisms of social tie formation such as homophily and triadic closure. These forces sharpen social segregation, which is reflected in fragmented social network structure. Geographical impediments such as distance and physical or administrative boundaries also reinforce social segregation. In this talk I give an overview of our recent work providing evidence that urban mobility, social network structure and income inequalities are interrelated. Investigating online social networks, we find that fragmentation of social networks is higher in towns where residential neighborhoods are divided by physical boundaries such as railroads, major roads, or rivers. We show that these urban geography features have significant relationships with income inequality via social network fragmentation. Then, using geo-located Twitter data in the 50 largest metropolitan areas in the US, we illustrate that social networks of residents from relatively poor neighborhoods are spatially concentrated around home. Those who commute to work to distant places, may create ties that enrich their social capital. Traces of cell-phone GPS coordinates, however, tell us that physical barriers in cities separate large shares of mobility. To mitigate urban inequalities, we need better access across barriers in cities and foster healthier social networks.

Videogames and the Gender Gap in Computer Science
by Claudia Meza-Cuadra
12.09.2024 11am CET
Abstract. In contrast to other STEM fields, over the last thirty years computer science has grown increasingly male-dominated. Using large-scale US survey data on field of education and occupation as well as data on computer and videogame playing from the mid-1980s to the early 2000s, I study the effect of the spread of videogames on the widening of the gender gap in computer science. Using two-way fixed effects regressions exploiting variation in the spread of videogames by state of birth and cohort, I find that for men, greater exposure to videogames when young is associated with (1) an increased probability of obtaining a bachelor’s degree in computer science (2) an increased probability of working in a computer-related occupation, and (3) a decreased probability of obtaining any bachelor’s degree. Among those who obtain a bachelor’s degree, a 20% increase in the spread of videogames in their cohort (while teenagers) is associated with a 10% increase in the gender gap in the probability of studying computer science, and a 14% increase in the gender gap in the probability of working in a related field. To address potential endogeneity, I instrument for videogame exposure using the early prevalence of videogame arcades by state combined with national sales of games released each year. The IV analysis confirms the results, suggesting that videogame exposure may be an important driver of the gender gap in computer science, and providing additional evidence of the long-term role of non-academic activities during childhood on education and career choices and outcomes.

Multilingual and Multicultural Misrepresentation in LLM Simulations of People
by Indira Sen
22.08.2024 11am CET
Abstract. Social simulation presents an intriguing and potentially revolutionary use case for Large Language Models (LLMs). Some researchers suggest that human biases encoded in LLMs, due to the data they’ve been trained on, can be exploited to mimic people with greater fidelity. Promising results have been found in using LLMs to simulate survey respondents, annotators, and even more complex simulations of groups of people. However, under which circumstances are the biases in LLMs true mirrors or people, and when are they distortions or exaggerations? To shed light on this question, I will present three case studies — 1) using LLMs to simulate data annotators, 2) using LLMs to generate training data for Machine Learning Models, and 3) using LLMs to simulate moral reasoning. Each of these studies shows the limitations of current LLM technology in faithfully and realistically simulating people due to an inability to represent minority and marginalized subgroups, especially for languages beyond English.

Fairness in link analysis ranking: analyzing HITS and PageRank on generative networks with homophily
by Ana-Andreea Stoica
26.07.2024 3pm CET
Abstract. Ranking algorithms have recently come under scrutiny for preventing minority groups from reaching higher ranking slots in applications like search and recommendation, thus reducing their visibility. In this talk, I will describe our recent work in diagnosing when and how algorithms that use network information may further bias against minority groups. We focus on two famous algorithms, PageRank and HITS, and analyze them empirically and theoretically, using a generative network model with multiple communities. We find that HITS amplifies pre-existing bias in homophilic networks, as compared to PageRank. We find the root cause of bias amplification in HITS to be the level of homophily present in the network. This work is joint with Augustin Chaintreau and Nelly Litvak and was published at The Web Conference ’24.

Socioeconomic segregation in adolescent friendship networks: A network analysis of social closure in US high schools
by Ben Rosche
04.07.2024 2pm CET
Abstract. Adolescent friendship networks are characterized by low interaction across both socioeconomic and racial lines. Using data from the National Study of Adolescent Health and a new exponential random graph modeling approach, this study examines the degree, pattern, and determinants of socioeconomic segregation and its relationship to racial segregation in friendship networks in high school. The results show that friendship networks are overall less socioeconomically segregated than they are racially segregated. However, the exclusion of low-SES students from high-SES cliques is pronounced and, unlike racial segregation, unilateral rather than mutual: many friendship ties from low-SES students to high-SES peers are unreciprocated. The decomposition of determinants indicates that about half of the socioeconomic segregation in friendship networks can be attributed to differences in socioeconomic composition between schools. The other half is attributable to students’ friendship choices within schools and driven by stratified courses (about 13 percent) as well as racial and socioeconomic preferences (about 37 percent). In contrast, relational mechanisms like triadic closure – long assumed to amplify network segregation – have only minor effects on socioeconomic segregation. These results highlight that SES-integrated friendship networks in educational settings are difficult to achieve without also addressing racial segregation. Implications for policymakers and educators are discussed.

Linking social network structure and function to social preferences
by Josefine Bohr Brask20.06.2024 11am CET
Update. This talk has been cancelled.
Abstract. Social network structures play an important role in the lives of animals by affecting individual fitness, and the spread of disease and information. Nevertheless, we still lack a good understanding of how these structures emerge from the behaviour of individuals. Generative network models based on empirical knowledge about animal social systems provide a powerful approach that can help close this gap. In this study: 1) we develop a general model for the emergence of social structures based on a key generative process of real animal social networks, namely social preferences for traits (such as the age, sex, etc. of social partners); 2) we use this model to investigate how different trait preferences affect social network structure and function. We find that the preferences used in a population can have far-reaching consequences for the population, via effects on the transmission of disease and information and the robustness of the social network against fragmentation when individuals disappear. The study thus shows that social preferences can have consequences that go far beyond direct benefits individuals gain from social partner selection. It also shows that these consequences depend both on the preference types, and on the types of traits they are used with. We discuss the implications of the results for social evolution.

Inequalities in International Trade of Digital Products
by Viktor Stojkoski
06.06.2024 11am CET
Abstract. Despite global efforts to harmonize international trade statistics, our understanding of digital trade and its implications remains elusive. Here, we introduce a novel method to estimate bilateral exports and imports for dozens of sectors, utilizing corporate revenue data from large digital firms. This approach enables us to quantify trade in digitally ordered and delivered products, including digital goods (e.g., video games), productized services (e.g., digital advertising), and digital intermediation fees (e.g., hotel rental), collectively termed digital products. By applying these estimates, we investigate the network of international trade in digital products and its implications for global inequality dynamics. Our findings illuminate four key aspects of digital trade. First, digital product exports exhibit a higher degree of spatial concentration than physical exports, suggesting network inequalities where developed economies (and tax havens) dominate digital trade flows. Second, the rapid growth of these exports, again predominantly within developed economies, underscores shifting dynamics that may intensify disparities between technologically advanced and developing regions. Third, the correlation between larger digital exports and the decoupling of economic growth from greenhouse gas emissions points to a widening gap in the benefits accruing from the digital economy. Fourth, the positive impact of digital product exports on the complexity of economies indicates a potential mechanism through which digital trade can affect economic inequality and alter network structures. These results offer valuable insights into the role of digital trade in shaping global economic inequality, providing a foundation for further research and policy consideration.

Network heterogeneity explains spatial heterogeneity in the ecology of pathogen strains
by Pourya Toranj Simin
23.05.2024 11am CET
Abstract. The homogeneity assumption in epidemiology assumes that all elements within a system share similar characteristics, which can oversimplify models and predictions. However, real-world heterogeneity significantly influences outcomes, especially in epidemiology, where various sources of heterogeneity impact infectious disease circulation.
In this presentation, I will discuss the impact of heterogeneity in social contact patterns on pandemic dynamics, focusing on COVID-19 variants. Early in the pandemic, variants of concern (VOCs) emerged, with increased transmissibility and immune escape, but competition dynamics varied across locations. We investigated how social contact networks and degree distribution heterogeneity affect variant co-circulation. Computational modeling revealed that the advantage of interacting variants is sensitive to population properties, with high dispersion in degree distribution slowing down the emergence of more transmissible variants, while accelerating the diffusion of variants escaping immunity. I will also discuss how we could validate our findings through empirical analysis using proxy data on contact networks.

The emergence of social identity
by Melody Sepahpour
02.05.2024 11am CET
Abstract. This study investigates the emergence of a social identity among individuals critical of COVID-19 vaccine policies in France. Amidst concerns over potential restrictions and obligations linked to the vaccine, a collective of individuals has convened both offline and online to vocalize their dissent and affirm their autonomy in vaccination decisions. Perceived as deviant by mainstream media, government, and society at large, this analysis explores the group’s emerging identity in response to unfolding events. Using computational analysis of tweets spanning the year following the vaccination campaign, this research explores how metrics including cosine similarity, pronoun usage, and outgroup labeling elucidate the emergence of social identity. Our findings reveal a pivotal shift in user engagement and identity dynamics following President Macron’s announcement mandating vaccination for health workers. Our results showed significant changes in linguistic patterns, suggesting the crystallization of a social identity in response to rejection. Furthermore, we identify a core group of proficient and consistent users who play a central role in fostering group cohesion. A focused examination surrounding Macron’s speech unveils how new entrants adapt their linguistic expressions to align with the emergent group identity. These findings shed light on the intricate mechanisms driving social identity formation amidst contentious public health policies, offering insights into the dynamics of online discourse and collective action.

Modeling misperception of public support for climate policy
by Ekaterina Landgren
25.04.2024 4pm CET
Abstract. Mitigating the consequences of climate change and reducing political polarization are two of the biggest problems facing society today. These problems are intertwined, since meeting international climate-mitigation targets requires implementing policies that accelerate the rate of decarbonization, and these policies can succeed only with widespread bipartisan support. Since the late 1980s, climate change has become a strongly polarizing issue in the United States. However, overall support for climate policy is high, with 66-80% of Americans supporting climate policies. Curiously, 80-90% of Americans underestimate public support for these policies, estimating the prevalence of support to be as low as 37-43%. (Sparkman et al. Nature communications 13.1 (2022): 4779.) The implications of such widespread misperception range from individual behaviors to legislative outcomes. Supporters of climate policy are more likely to self-silence if they believe their peers do not support it, and politicians are less likely to promote policies they believe to be unpopular. Here we present an agent-based social-network model of public perception of support for climate policy grounded in previous empirical studies and opinion surveys. We find that homophily effects alone do not explain widespread misperception. However, our network analysis suggests that disproportionate representation of opposition to climate policy among central nodes can offer a potential explanation for underestimation of public support. In order to assess the validity of this assumption in the real world, we explore the coverage of climate policy in U.S. news media in order to inform our model.

Quantifying spatial heterogeneity and urban segregation on networks through diffusion
by Sandro Sousa
11.04.2024 11am CET
Abstract. Socioeconomic segregation has an important role in the emergence of large-scale inequalities in urban areas. Most of the available measures of spatial segregation depend on the scale and size of the system under study, or neglect large-scale spatial correlations, or rely on ad-hoc parameters, making it hard to compare different systems on equal grounds. In this talk, I will show a family of non-parametric measures for spatial distributions, based on the statistics of the trajectories of random walks on graphs associated with a spatial system. These difusion-based quantities provide a consistent estimation of segregation in synthetic spatial patterns, and they were used to analyse the ethnic segregation of metropolitan areas in the US and the UK. They also used to understand the disproportionate incident of COVID-19 cases among African Americans. This approach, as measured through diffusion on graphs, allows us to quantify and compare sociospatial phenomena in urban areas having different sizes, shapes, or peculiar microscopic characteristics.

Surprising phenomenon in the math of network models
by Shankar Bhamidi
28.03.2024 2pm CET
Abstract. The goal of this talk is to both convey the importance of domain experts (like those involved in the current initiative) to guide mathematicians like myself in their choice of problems, as well as convey the importance of math techniques in understanding proposed network models, through three personal research experiences: 1. In the context of one fundamental static model in social networks, the exponential random graph model (ERGMs) we will describe what math probability says in one specific (“ferromagnetic”) regime (joint work with Allan Sly and Guy Bresler). 2. In the context of change point detection for dynamic network models, we will describing the impact of hidden long range dependence on the evolution of such models (Joint work with Sayan Banerjee, Iain Carmichael, Jimmy Jin and Andrew Nobel). 3. In the context of attributed network models, we will describe what a theoretical analysis say about the behavior of centrality mechanisms such as page rank and degree centrality and the surprising efficacy of page rank driven sampling in the specific setting of sampling from rare minorities (Joint work with Nelson Antunes, Sayan Banerjee, and Vladas Pipiras).

Social inequalities in ballet: implications for career success
by Yessica Herrera
07.03.2024 11am CET
Abstract. Global economic inequality remains a complex social challenge, impacting various facets of our society, including the arts. There is growing evidence suggesting inequalities in artists’ access to economic growth and leading positions in their careers. Hence, understanding the social dynamics of inequalities within the arts has become increasingly crucial. In particular, performing arts have long mirrored and perpetuated social inequalities, originating among white male aristocrats. Today, these disparities persist as systemic unequal access to institutional prestige and a disadvantaged professional environment for women. Recent decades have seen significant improvements in quantifying the behaviors and impact of scientists through the development of new methodologies, such as network science and the science of science, revealing patterns underlying successful careers. While performance in the arts has long been difficult to quantify objectively, research suggests that professional networks and prestige of affiliations play an important role in predicting career success, similar to observations in science. In this talk, we turn our attention to ballet—a mainstream performing art steeped in historical inequalities—as it allows us to investigate the interplay of individual performance, institutional prestige, and network effects quantitatively. We analyze data on competition outcomes from 6363 ballet students affiliated with 1603 schools in the United States, who participated in the Youth America Grand Prix (YAGP) between 2000 and 2021. Through network analysis, multiple logit models, and matching experiments, we provide evidence that schools’ strategic network position bridging between communities captures social prestige and predicts the placement of students into jobs in ballet companies. This work highlights the importance of institutional prestige on career success in ballet and showcases the potential of network science approaches to offer quantitative perspectives for career development beyond science. Moreover, network science research has proven useful in shedding light on the social components of gender inequalities in the field, emphasizing the need for more collaborative efforts to address systemic inequalities within the arts in future research.

Human-Algorithm Decision-Making Under Imperfect Proxy Labels
by Luke Guerdan
29.02.2024 2pm CET
Abstract. Across domains such as medicine, employment, and social media, predictive models often target labels that imperfectly reflect the outcomes of interest to experts and policymakers. For example, clinical risk assessments deployed to inform physician decision-making often predict measures of healthcare utilization (e.g., costs, hospitalization) as a proxy for patient medical need. These proxies can be subject to outcome measurement error when they systematically differ from the target outcome they are intended to measure. In this talk, we discuss five sources of target variable bias that can impact the validity of proxy labels in human-algorithm decision-making tasks. We develop a causal framework to disentangle the relationship between each bias and clarify which are of concern in specific decision-making settings. We first leverage our framework to re-examine the designs of prior human subjects experiments that investigate human-algorithm decision-making and find that only a small fraction examine factors related to target variable bias. Next, we propose an algorithmic technique which, given knowledge of proxy measurement error properties, corrects for the combined effects of these challenges. We demonstrate the utility of our approach via experiments on real-world data from randomized controlled trials conducted in healthcare and employment domains. Our work underscores the importance of considering intersectional threats to model validity during the design and evaluation of human-algorithm decision-making workflows. We conclude by discussing the implications of imperfect proxy labels on efforts to adequately measure and mitigate network inequality.

Cooperation and Inequality in Stochastic Models of Growth
by Jordan Kemp
15.02.2024 3pm CET
Absract. Group formation and collective action are fundamental to cooperative agents seeking to maximize resource growth. Researchers have extensively explored social interaction structures via game theory and homophilic linkages, such as kin selection and scalar stress, to understand emergent cooperation in complex systems. However, we still lack a general theory capable of predicting how agents benefit from heterogeneous preferences, joint information, or skill complementarities in statistical environments. In this talk, we derive general statistical dynamics for the origin of growth and cooperation based on the management of resources and pooled information. Specifically, we show how groups that optimally combine complementary agent knowledge in statistical environments maximize their growth rate. We show that these advantages are quantified by the information synergy embedded in the conditional probability of environmental states given agents’ signals, such that groups with a greater diversity of signals maximize their collective information. It follows that, when constraints are placed on group formation, agents must intelligently select with whom they cooperate to maximize the synergy available to their own signal. We then show how heterogeneity across groups drives resource inequality, which can be mitigated across similar groups through learning in shared environments. These results show how the general properties of information underlie optimal collective formation and drive the emergence of inequality in social systems.
Disclaimer: The list of speakers for this lecture series was compiled through an open nomination process that took place from December 11, 2023, to January 24, 2024. We received a total of 19 nominations, with a diverse pool of 9 men and 10 women. The final list of confirmed speakers includes 9 men and 8 women. We are committed to transparency and equal opportunities in our speaker selection process, and we encourage nominations from all qualified individuals regardless of gender, race, ethnicity, or any other protected characteristic or social capital.